1 Introduction
Globule is a system that performs Web site replication. This means that WWW
documents are copied across multiple machines where clients can access them.
A document has one origin server, which is the machine where it is
edited and published. The origin server usually belongs to the owner of the
document. In addition, a document can have any number of replica
servers, which host copies of the original document and deliver them to the
clients. Replica servers do not necessarily belong to the owner of the
document.
Replicating a Web site has multiple advantages:
-
The documents remain accessible to clients even if some servers
are down (provided that at least one of them is alive)
- The performance of the site is optimized, because clients can
fetch documents from a server close to them. Shorter
server-to-client transfer distances usually mean faster downloads.
- Multiple servers are better at handling a flash crowd than a
single server. Flash crowds are events where the request load of a
given site increases by several order of magnitudes within a few
minutes or seconds. This frequently happens, for example, when
a page is being
linked to by Slashdot.
- Playing with multiple servers is fun!
Globule is designed as a third-party module for the
Apache version 2.0.x Web
server.
You will therefore benefit from all great
features that made Apache the Number One Server On The Internet. In
addition, Globule will provide replication functionalities to this
server.
1.1 Globule Features
Globule provides the following features:
-
Replication: Web sites (or parts thereof) can be replicated
across multiple servers, even if the involved servers do not belong to the
same persons.
- Client redirection: Clients accessing the site are
automatically redirected to one of the replicas. This can be done using HTTP
or DNS redirection. Moreover, Globule supports several policies which allow
one to decide to which replica each client should be redirected.
- Fault-tolerance: Each Globule server periodically checks the
availability of the machines holding its replicas. In case one replica site
is down or misconfigured, it will stop redirecting client requests to this
replica until it has recovered. Globule also supports the creation of
backups of the origin server so that the site will function correctly even
if the origin server is down.
- Monitoring: Globule allows administrators to monitor the
behavior of their system in three different ways. First, the logs of
requests addressed to replicas are transfered back to the origin server to
rebuild a ``global access log.'' Second, Globule can attach a cookie with
each delivered document containing information on how this request was
treated. Lastly it is possible to collect internal statistics on the usage
pattern and process them using configurable filters.
- Adaptive replication: There are many ways by which a given
document can be replicated and document updates can be taken into
account. Unlike many other systems, Globule does not consider that there is
one policy that is best in all cases [2]. Instead, it
supports multiple policies and periodically checks for each document which
policy is likely to offer best performance. When the current policy is not
optimal, it is automatically replaced with the best one.
- Dynamic document replication: Globule can not only replicate
static documents but also scripts that are executed at the server to
generate content, such as PHP scripts. The scripts themselves are
replicated and executed on replica servers. If a PHP script accesses a
MySQL database, then Globule can also cache database queries to further
optimize performance [3].
- Configuration server: The
Globe Broker System (GBS) is a web
site where Globule users can register, meet each other, and decide to
replicate each other's content. Configuration files are automatically
generated, which saves most users from the need to read most of this
documentation.
In addition to the current features, we are currently conducting research on
the following topics. When research is finished, these features will be
integrated into Globule.
-
Latency estimation: We developed a nifty way to estimate
the latency between any pair of nodes in the Internet, that is the
delay it takes to transfer a bit of information from one machine to
the other. Instead of sending gazillions of messages between every
pair of machines, our method is based on a very low number of actual
measurements [4].
A prototype is running fine, but it will take a while before we can
integrate it into the Globule distribution.
- Replica placement: Based on latency estimations, we are
now capable to analyze the location of clients requesting a Web
site, and derive a set of locations where replica servers should
ideally be placed [5].
- Flash-crowd prediction and pro-active management:
The request rate of a web-site can sometimes change drastically within
minuts such as when it is being referred in a popular bulletin board such as
SlashDot. Flash-crowds, as they are called, often jam web-servers to the
point where they become unusable. We are working on techniques to detect
the early stages of flash-crowds, and pro-actively replicate the concerned
sites such that they can serve every request
efficiently [1].
1.2 Terminology
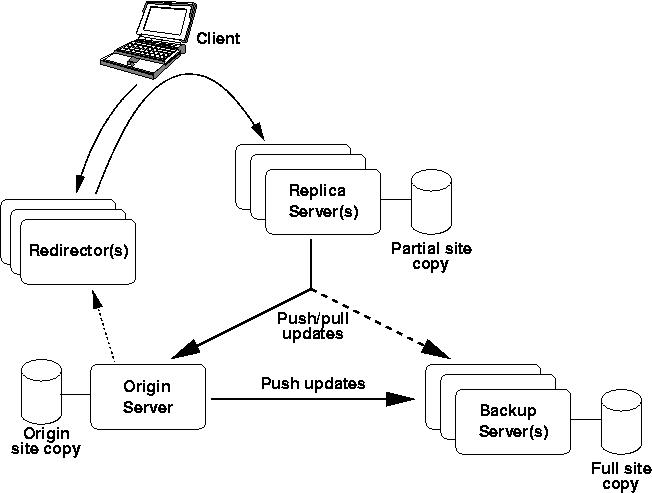
Globule makes a strong distinction between a site and a server.
A site is defined as a collection
of documents that belong to a given user.
A server is a machine connected
to a network, which runs an instance of the Globule software. Each server may
host one or more sites, that is, be capable of delivering the site's content
to its clients. As shown in Figure 1, servers can be classified
in four categories according to the role they play with respect to this site.
Each site has one Origin server,
which typically belongs to the site owner. The origin contains the
authoritative version of all documents of the site. It is also in charge of
making all decisions on where, when and how replication of the site should
take place.
The origin server is helped delivering
documents by any number of replica servers. Replica servers replicate
documents locally and deliver them to the clients. A replica server for a site
is typically operated by a different user than its origin, so the replica's
administrator may impose restrictions on the amount of resources (disk space,
bandwidth, etc,) that the hosted site can use on their machine. As a result,
each replica server typically contains only a partial copy of its hosted
site. Similarly to a caching proxy, when requested for a document not present
locally, a replica server fetches the document from its origin before
delivering it to the client.
When a replica server needs to fetch a
document from the origin, it obviously requires that the origin server is
available to deliver the document. Remember, however, that the origin server
is typically simply the desktop machine of the site owner. Such machines are
often unavailable for a multitude of reasons ranging from a voluntary shutdown
to a network failure. To overcome this problem, the origin server can define
any number of backup servers. Backups are very similar to replica
servers, except that they hold a full copy of the hosted site. If a
replica cannot contact the origin server, then it can obtain the requested
information from any backup. Backup servers also perform the role of a
regular replica server, helping serving the content of a site.
Once documents have been replicated
across multiple servers, one needs to automatically redirect client requests
to one of the replicas. This is done by one or more redirectors,
which know the list of all replica and backup servers for the site, monitor
their status, and redirect client requests to one of the currently available
servers. Redirectors can use two different mechanisms for redirection: in
HTTP redirection a redirector responds to HTTP requests from the clients with
a redirection return code 302. Alternatively, in DNS redirection, a
redirector implements a specialized DNS server that resolves the site's name
into the IP address of the destination replica.
It should be clear that the distinction between origin, replica, backup and
redirector servers refers only to the role that a given server takes with
respect to any given site. The same server may for example simultaneously act
as the origin and one of the redirectors for its owner's site, as a backup for
a few selected friend's sites, as a replica for other sites, and as a
redirector for yet other sites.
1.3 Known issues/limitations
-
Globule only works with Apache version 2.0.x. It does not
work with Apache version 1.3.x, and there is no plan on changing
this.
Apache version 2.1/2.2 is not supported up to and including Globule release
1.3.1. This may change in future releases of Globule.
globule@globule.org
February 27, 2006
|